In Data Vault 2.0, there are several types of advanced objects that can be used to model and manage data in an enterprise data warehouse. These include:
Basic objects
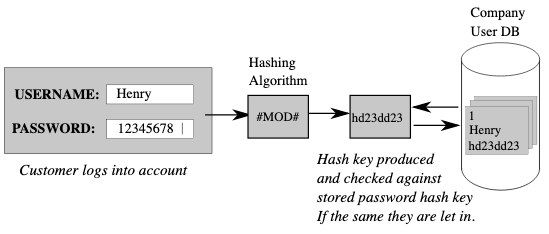
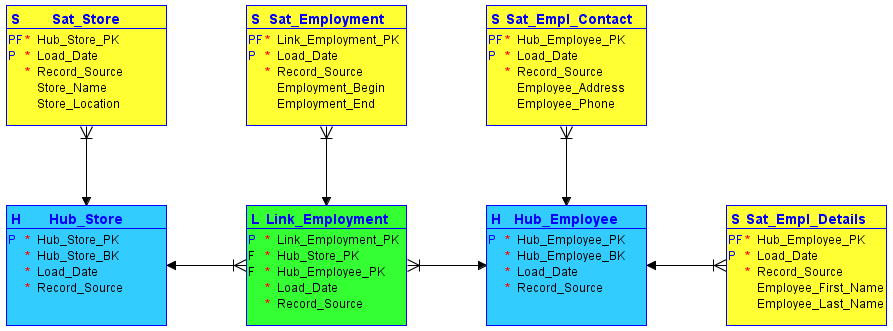
- Hubs: A hub is a central point in the Data Vault model that represents a unique business entity. Hubs are used to store the unique business keys and attributes of an entity, and they act as the central reference point for all related satellite and link objects.
- Satellites: A satellite is a supporting object in the Data Vault model that stores additional attributes and historical data about a business entity represented by a hub. Satellites are used to capture changes in the attributes of an entity over time.
- Links: A link is a connecting object in the Data Vault model that represents a relationship between two or more business entities. Links are used to storing the relationships between entities and the attributes that describe those relationships.
Intermediate objects
- Bridges: A bridge is an advanced object in the Data Vault model that is used to model many-to-many relationships between entities. Bridges are used to store the relationships between entities and the attributes that describe those relationships in a way that is more flexible and efficient than using multiple links.
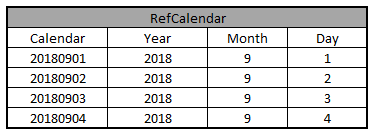
- Reference Data: Reference data is a type of satellite object that stores data that is used to classify or categorize other data in the Data Vault model. Reference data can be used to store codes, descriptions, and other attributes that are used to describe business entities in the Data Vault model.
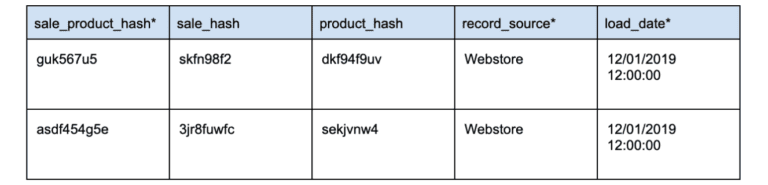
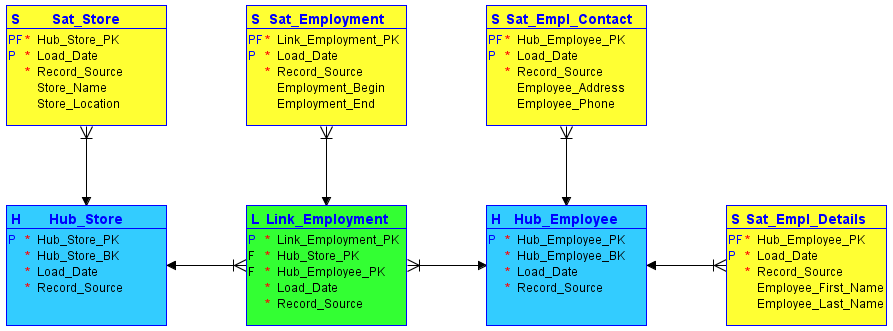
- Link Satellite (LSAT): link satellite is a type of object that is used to store additional attributes and historical data about a link object in the Data Vault model. Link satellites are used to capture changes in the attributes of a link over time, and they are typically used to store data that is specific to the link object and not relevant to the entities that are related by the link.
Link satellites are implemented as tables in a database, and they are typically composed of three columns: a link identifier, a satellite identifier, and a satellite attribute column. The link identifier is a foreign key that references the link object, and the satellite identifier is a unique identifier for the link satellite. The satellite attribute column is used to store the attributes and data that are specific to the link satellite.
Link satellites are used in conjunction with hubs, satellites, and links in the Data Vault model. The hub stores the unique business keys and attributes of an entity, the satellite stores additional attributes and historical data about the entity, and the link is used to represent the relationship between the entities. The link satellite is used to store data about the link object itself and the relationship between the entities.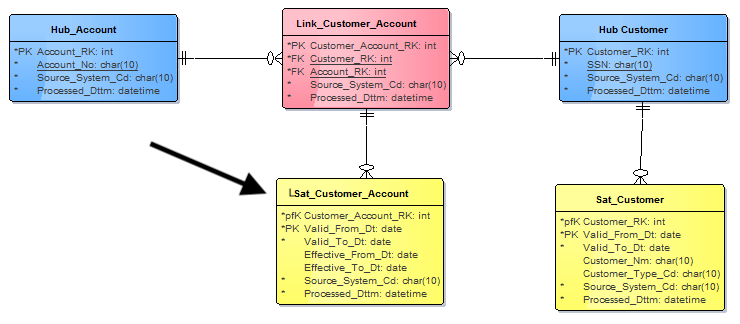
Image copyright: Anna Brown (https://communities.sas.com/t5/SAS-Communities-Library/Using-SAS-DI-Studio-to-Load-a-Data-Vault-Part-II-DV2-0/ta-p/221776)
Advance objects
- Non-historized Links (NHLINK): A non-historized link is a type of link object in the Data Vault model that is used to represent a current or active relationship between two or more business entities. Non-historized links do not store historical data about the relationships between entities, and they are typically used to represent relationships that are expected to remain unchanged over time.

Image copyright: Scalefree (https://www.scalefree.com/modeling/the-value-of-non-historized-links/) - Point-in-Time (PIT) Tables: A Point-in-Time (PIT) table is a type of table in the Data Vault model that stores historical data about the state of a business entity at a specific point in time. PIT tables are used to capture snapshot data about an entity and can be used to track changes in the attributes of an entity over time.
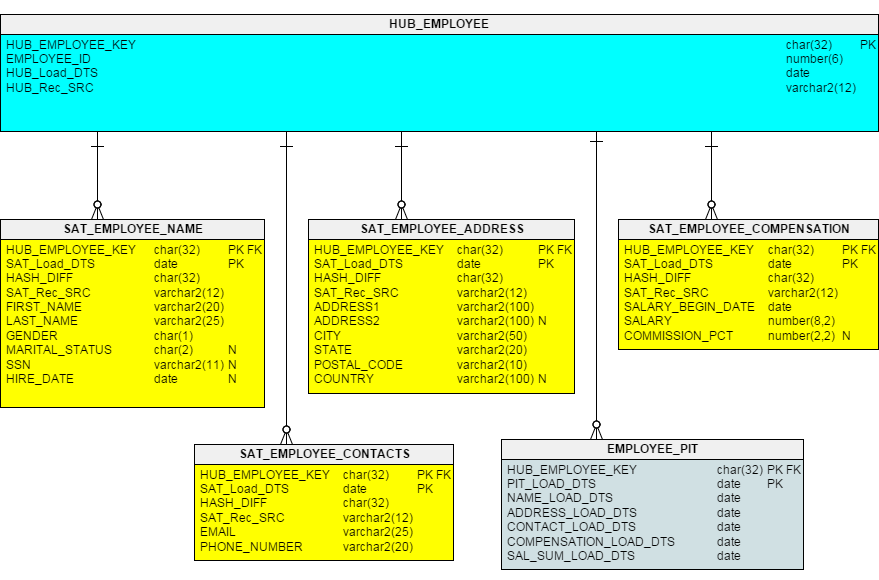
Image copyright: KentGraziano (https://vertabelo.com/blog/data-vault-series-the-business-data-vault/) - Same as link (SAL): Same as Link is a type of connecting object that is used to represent a relationship between two or more business entities that are considered to be the same or equivalent. SALs are used to eliminate redundancy and consolidate data in the Data Vault model.
SALs are typically used when two or more entities represent the same real-world concept or object, but they have different business keys or identifiers. For example, a customer may have multiple accounts with a company, and each account may have a different account number. A SAL could be used to link the different accounts together and indicate that they represent the same customer.
Image copyright: Michael Olschimke (https://www.sciencedirect.com/topics/computer-science/raw-data-vault)
Did I miss any object? please let me know in the comments section below.